Introduction
According to researchers from Boston University, among other research groups that study dreaming:
"It is believed that the human brain is incapable of “creating” a new face."
In fact, this is something at which AI is already over the human capabilities. Don't you believe me? Go to thispersondoesnotexist.com and check it out by yourself. AI is capable of generating new faces, something that has been said to be impossible to be done by humans for years. How is this possible? Is AI capable of generating anything beyond human comprehension? Let's dive into what this so-called generative algorithms are and how do they work.
What are generative algorithms?
Basically, Generative Artificial Intelligence is AI capable of generating text, images, or other data using statistical generative models. That is, in layman's words, a model that learns the probability distribution of a given type of data and is able to create new samples from that learned latent space. These models are usually trained using an unsupervised or semi-supervised approach.
Generative Artificial Intelligence
In a few words, generative models allow us to generate new data that meets the probability distribution of the data which the model was trained with. In order to tell how good a generative AI model is - or in other words, to evaluate it - there are three main features to keep an eye on: quality, diversity, and speed.
- Quality: It refers to how accurately and convincingly the generated outputs resemble the original data or meet the desired characteristics.
- Diversity: It measures the variety or novelty of the generated outputs.
- Speed: It refers to how quickly the model can generate new samples.
There is, as usual, a tradeoff between these three characteristics, and surprisingly, based on this tradeoff, we can find three main types of generative models: Those models that produce high quality and diverse outputs are usually (denoising) diffusion models, though these models are not especially fast; those that infer at great speed and produce diverse outputs are usually Variational Autoencoders (VAEs), but they usually lack quality; and finally, the models that infer at high speeds and produce outputs of great quality are usually Generative Adversarial Networks (GANs).
As we see, there are several types of generative models, which are evolving fast by joining forces and taking the best of each model. Let's go over each category to gain better intuition on how each of them works.
Diffusion models (DDPM)
Denoising Diffusion Models were firstly introduced in Deep Unsupervised Learning using Nonequilibrium Thermodynamics, where the authors introduced a new method for modeling complex datasets by systematically and slowly destroying structure in a data distribution through an iterative forward diffusion process and then learning a reverse diffusion process that restores structure in data. In simpler terms, they propose a method that learns to invert the stochastic process that transforms data into noise.

DDPMs
Since the publication of the paper in 2015, thousands of works around diffusion models have appeared: Denoising Diffusion Models by researchers of UC Berkeley demonstrates how random noise can be transformed into high quality images; Diffusion Models Beat GANs on Image Synthesis by OpenAI researchers test different architectures of diffusion models by performing a series of ablations (removal of certain parts of the algorithms) to demonstrate that diffusion models could beat GANs in generating high quality images; or High-Resolution Image Synthesis with Latent Diffusion Models aka Stable Diffusion by researchers of the Computer Vision & Learning Group at LMU demonstrated how Diffusion Models could run on consumer hardware, addressing the problem of high computational costs.
There is no secret that this kind of models revolutionized this line of work, and its applications on generating image or text data are very sound in the field.
Variational Autoencoders (VAEs)
VAEs were initially introduced by Kingma and Welling from the Universiteit van Amsterdam with the paper Auto-Encoding Variational Bayes in 2013. In the paper, they propose a framework called variational autoencoders (VAEs) that combines deep learning with probabilistic modeling, with an aim to learn efficient representations of complex data distributions by simultaneously training an encoder and decoder network. The "variation" in VAEs refers to the probabilistic nature of the latent space representation. In traditional autoencoders, the encoder network maps input data to a fixed-size latent vector, and the decoder network reconstructs the input from this latent representation. In VAEs, rather than encoding data into a deterministic latent vector, the encoder outputs parameters of a probability distribution (typically Gaussian) that describes the latent space.
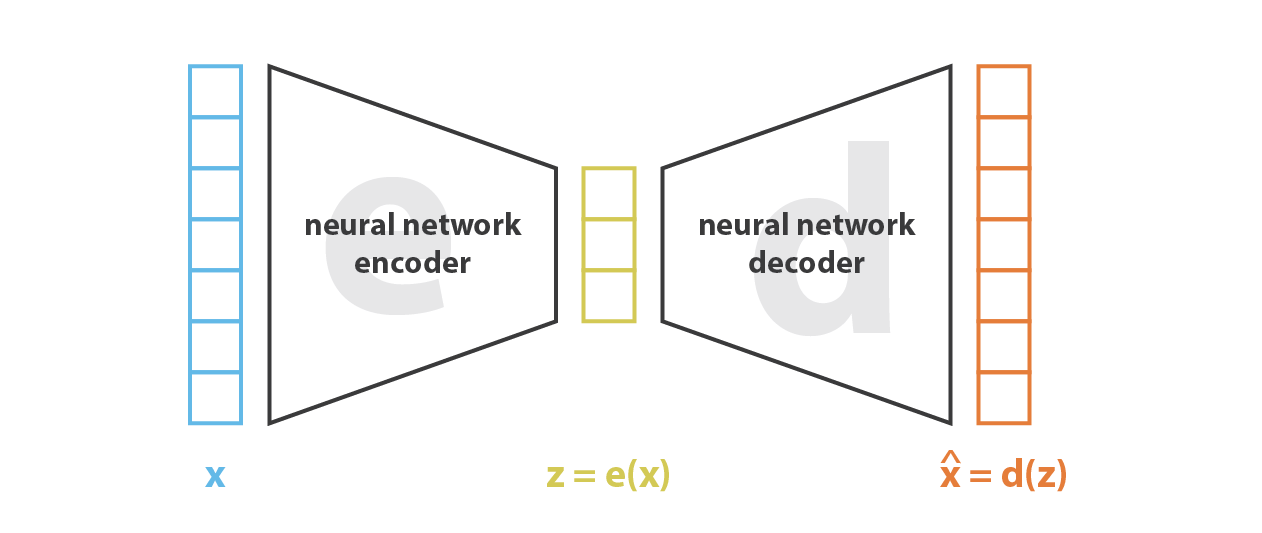
VAEs
This kind of architecture works by training an encoder-decoder neural network. Basically, the network encodes the data into a compact latent space representation - that is, a low-dimensional representation of original data - and then decodes this representation back into the original data space. By jointly optimizing these objectives, VAEs learn to generate new data samples by sampling from the learned latent space distribution, among other tasks such as data compression.
As per Awesome-VAEs, there have been hundreds of works on Variational Autoencoders over the past few years, such as NVAE: A Deep Hierarchical Variational Autoencoder where the authors from NVIDIA introduce a deep hierarchical VAE built for image generation using depth-wise separable convolutions and batch normalization. This hierarchical architecture is like a series of stages, where each stage refines the output of the previous stage. This hierarchical structure allows the model to capture complex patterns in a more structured and organized manner. For example, in image generation tasks, lower levels of the hierarchy could capture basic shapes and textures, while higher levels might focus on more abstract features.
Also, the original VAE authors released in 2019 An Introduction to Variational Autoencoders with aims to provide an introduction to variational autoencoders and some important extensions.
Generative Adversarial Networks (GANs)
Generative Adversarial Networks presented by Goodfellow et al. in 2014 are a kind of generative AI algorithms which, in short, pit two neural networks against each other in a sort of a competing fashion, so-called adversarial process. One of these networks is called a Generator and the other one a Discriminator. The generator network captures the data distribution and generates new data instances or samples based on random noise or some other input data. The discriminator network, on the other hand, estimates the probability that a sample came from the training data rather than the generator.
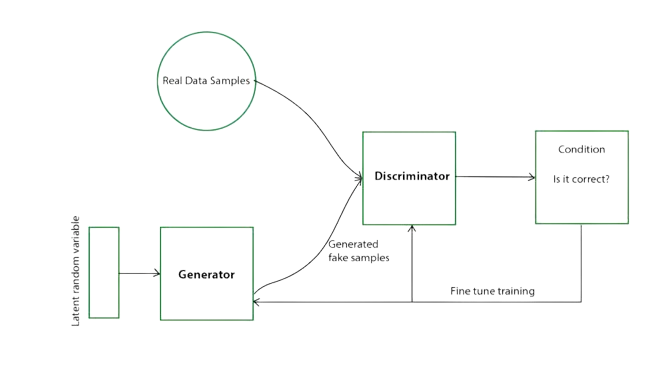
GANs
Basically, the generator gets better trying to fool the discriminator, which at the same time gets better at identifying synthetic samples. According to the cited paper, in the case where the generator and discriminator are defined by MLPs, the entire system can be trained with backpropagation and there is no need for any Markov chains. However, one of the many caveats of GANs is that they are very hard to train.
There is no doubt that GANs are very popular, and in the last couple of years, there have been several works revolving around them: In 2017, researchers from FAIR introduced Wasserstein GAN, a new way to train GANs that differed from the classical approach of learning the PDF (Probability Density Function). They introduced a new distance called Wasserstein distance - also known as the Earth Mover's distance - as a metric to measure the dissimilarity between the distributions of real and generated data. Later in 2019, A Style-Based Generator Architecture for Generative Adversarial Networks aka StyleGAN was published by NVIDIA researchers where they proposed an alternative generator architecture for generative adversarial networks, borrowing from style transfer literature, which led to better interpolation properties i.e. improving the process of generating new images by smoothly transitioning between two or more points in the latent space and better disentangles the latent factors of variation i.e. representing each feature of the input data separately in the latent space. Another example of the great work around GANs is Self-Attention Generative Adversarial Networks by Google Brain scientists, which in summary incorporates the well-known self-attention mechanism into both the generator and the discriminator.
Applications and challenges
Generative models have several use cases that range from language to visual and audio. We have seen it in Large Language Models (LLMs), the creation of 3D images, avatars, or videos, but also in other fields such as developing new protein sequences to aid in drug discovery. There is no doubt that generative models, indeed, have great capabilities, but nothing comes without a cost and this kind of models present a series of challenges, some of which are presented below:
- Data bias: Generative AI models can perpetuate biases present in the training data, leading to unfair or discriminatory outcomes.
- Overfitting: Models may memorize training data rather than learning generalizable patterns, resulting in poor performance on new data.
- Lack of control: Generated outputs may lack controllability, making it challenging to ensure specific desired outcomes.
- Ethical concerns: AI-generated content can raise ethical dilemmas regarding ownership, authenticity, and responsible use.
- Privacy risks: Generating realistic data can pose privacy risks if the generated content resembles sensitive or personal information.
Generative models are absolutely amazing but with great power comes great responsibility, and there is no doubt that being able to identify whether a piece of data is real or generated by AI is going to be a great challenge. At AIdentify, I'm working to solve exactly this and generative models are something that I'm immersing myself into to better understand the needs to identify this kind of data.
Sources
Apart from the cited papers, other sources which I consulted to write this post are: